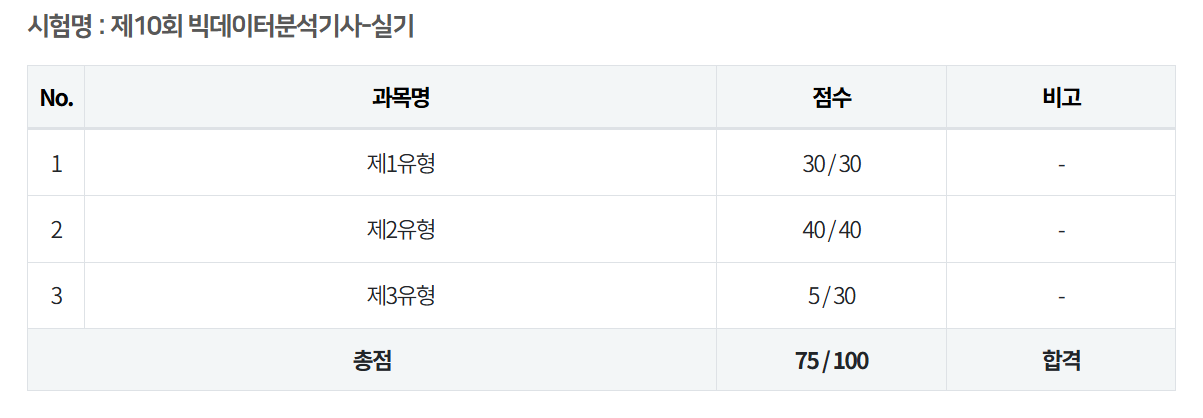
빅분기 실기 공부
1. 어떻게 나오는지 느껴보자
일단 무작정 책 부터 펼치지는 않았고 유튜브 강의를 먼저 보았다.
https://youtu.be/xgAQ-jcsYho?si=TcxpoG0ioEK25PCT
일단 이 아답터 유튜브는 꼭 봐야 한다.
필기 공부때도 많은 도움을 받았어서 이 강의영상 부터 보았다.
1, 2, 3 유형마다 영상이 하나씩 있고 문제들이 어떻게 나오는지, 어떻게 풀어나가는지 대략적으로 확인할 수 있다.
이 영상을 보고나서 어떻게 공부해야할지, 책을 살지말지 이런 판단을 내릴 수 있었다.
내 판단은 책을 굳이 사지 않아도 인터넷에 데이터마님, Kaggle 같은 것들을 활용하여서 충분히 공부할 수 있겠다 라는 생각이 들었다.
2. Kaggle을 활용하자
https://www.kaggle.com/datasets/agileteam/bigdatacertificationkr
Big Data Certification KR
퇴근후딴짓 의 빅데이터 분석기사 실기 (Python, R tutorial code) 커뮤니티
www.kaggle.com
내가 책을 구매하지 않은 가장 큰 이유가 Kaggle에 있다.
여기에 거의 모든 유형의 문제들이 다 정리되어 있었다.

1유형 공부
Kaggle에는 총 35가지의 유형이 정리되어 있는데 여기서 즁요도가 높은(별이 있는) 유형들만 공부했었다.
여기서도 생각보다 외워놔야 할것들이 많아서 정리는 필수이다.
나는 정리를 노션으로 정리하였다.
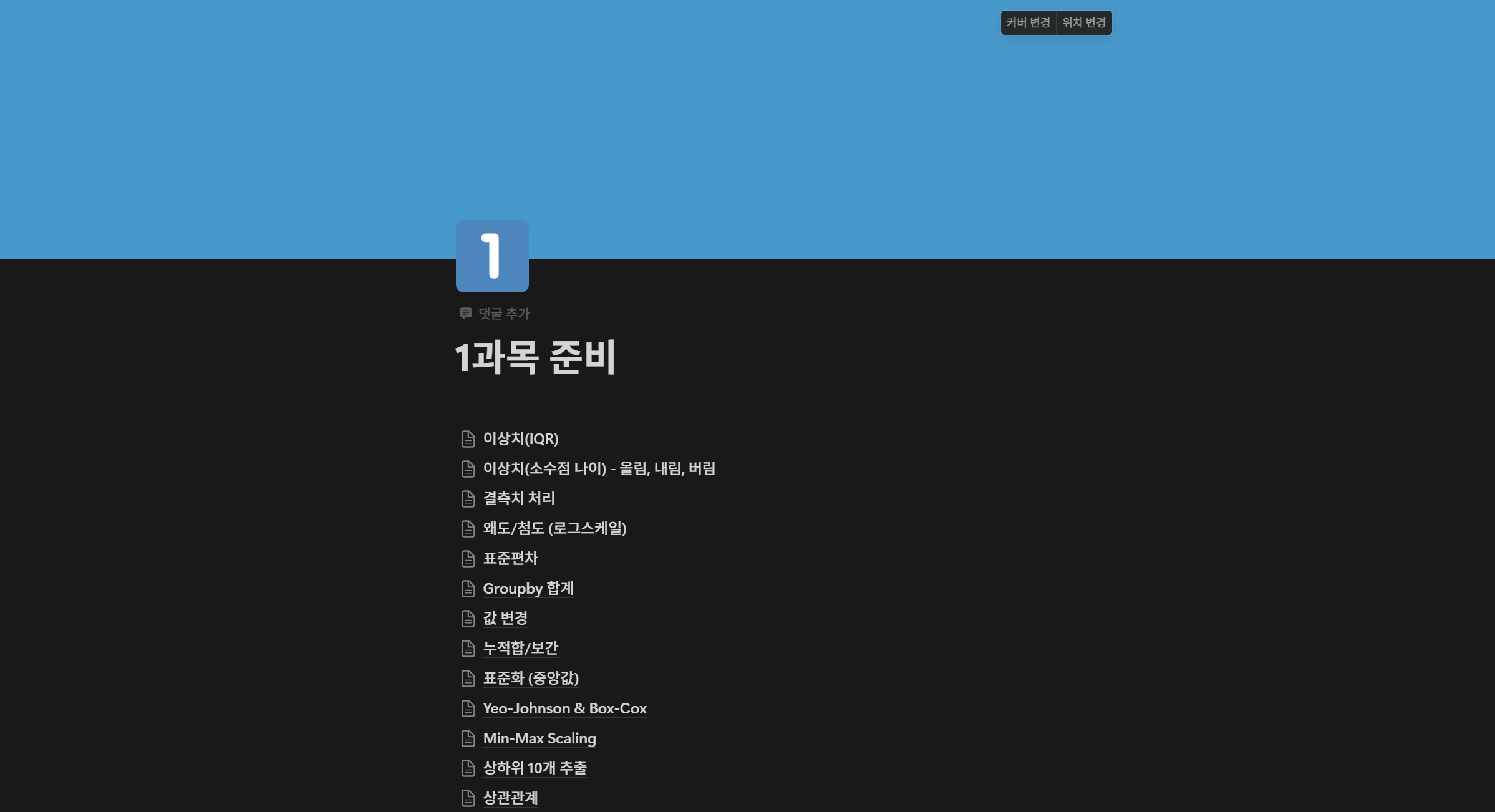
이렇게 한 유형들 끼리 정리를 해놓고 처음 알게된 정보들을 따로 모아서 정리해놓았다.
그렇게 해놓으면 어떤 유형이 나오는지, 내가 어떤것들을 모르는지 정확히 알게된다.

2유형 공부
2유형은 생각보다 별로 할게 없었다.

내가 전공때 배웠던 내용들과 많이 겹쳐서 쉽게 할 수 있었다.
그래서 꿀팁을 주자면
여러가지 전처리 방법 + 여러가지 모델 의 조합을 하나씩 매칭해보면서 최적의 성능을 찾는것을 추천한다.
예를 들어 전처리 중에서 스케일링을 할 때 여러가지 방법이 있다.
1. get_dummies()
2. 분류형일 때 : LabelEncoder() / OneHotEncoder()
3. 회귀형일 때 : StandardScaler() / MinMaxScaler()
여러가지 스케일링 방법을 사용하여서 데이터를 변환시킨다. 그 후
1. RandomForest
2. Linear model
3. XGBoosst
4. LightGBM
사용 가능한 여러가지 모델들이 있다. 그래서 다양하게 모델들을 사용해본 후 최적의 조합을 찾아보는것이 중요하다.
이번 빅분기 10회 실기에서는 여러가지 방법 중 가장 성능이 높았던 조합은 get_dummies() + XGBoostRegressor() 조합이었다.
하이퍼파라미터 최적화는 과적합이 일어날 수 있어 사용하지 않았다. 하지 않아도 최적 조합을 찾는것 만으로도 높은 성능을 가질 수 있었다.
3유형 공부
3유형은 단 1도 보지않았다,,,
하지만 시험을 치면서 든 생각은 나처럼 3유형을 완전히 버리는 사람들이 많아서 정확한 오답률을 집계하기 어려운 유형이겠다 라는 생각이 들었다.
그래서 막상 공부를 해본다면 문제가 쉬울수도 있을거 같다.
요즘 경향이 1유형을 더 어렵게 낸다는 말이 있어서 3유형을 함께 공부한다면 합격률을 많이 올릴 수 있을거 같다.