What is Reinforcement Learning?
강화학습의 사전적 정의는
순차적 의사결정 문제에서 누적 보상을 최대화 하기 위해 시행착오를 통해 행동을 교정하며 학습하는 과정
이다.
처음 이 말을 들었을 때는 와닿지가 않을 것이다.
그래서 아래 그림과 함께 본다면 이해에 도움이 될것이다.

일단 강화학습은 x값(독립변서), y값(종속변수)이 따로 존재하지 않는다.
오직 보상값만 존재하게 된다.
이때 보상값이란 인공지능(agent)이 환경(Environment)에서 어떠한 행동(Action)을 했을 때의 결과값을 목표값(Goal)을 기준으로 좋은 action 이었는지, 나쁜 action 이었는지 판단할 수 있는 가중치 라고 할 수 있다.
이 말은 위의 그림을 풀어서 설명한 것과 같다.
조금 더 설명을 해보자면
어떠한 상황(state), 또는 환경(Environment) 에서 인공지능(agent)이 여러 행동(Action)을 할 수 있다.
예를 들어보면 오목을 하는데 유저(이때 유저는 인공지능을 의미함)가 여러 수를 둘 수도 있다.
아래 오목 판에서 유저가 검은 돌이라고 했을 때를 생각해보자.

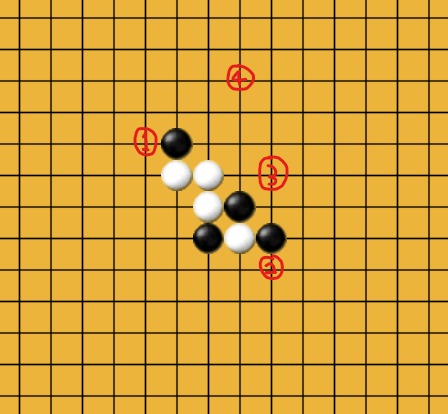
유저가 할 수 있는 행동(Action)은 흰 돌의 삼 을 막을 수 있는 1, 2번의 자리에 둘 수도 있고, 삼을 만들 수 있는 3번 자리에 둘 수도 있고, 정말 어이없이 4번의 자리에 둘 수도 있다.
이 4가지의 action들을 평가해보자. 1, 2번에 두게 된다면 흰 돌의 공격을 막을 수 있어 게임을 이어 나갈 수 있다.
3번에 두는 action은 삼을 만들어 공격을 할 수는 있으나 흰 돌의 공격에 의해 패배할 것이다.
4번 action은 안 좋은 action임이 자명하다.
자 여기서 가장 좋은 action은 무엇일까?
바로 1, 2번 action이다.
그렇다면 이 action들의 보상값(reward)은 큰 값을 주게 될 것이다.
3번 action의 reward는 그 보다는 작을 것이고
4번 action의 reward는 아마 음수가 되지 않을까 싶다.
인공지능(Agent)과 주변 환경(Environment)은 상호보완하여 발전된다.
agent가 action을 했을 때 Environment에 좋은 결과면 reward를 주게 된다.
그 reward가 가산된 환경을 다시 인공지능에 주입하게 되어 위의 그림과 같은 사이클이 만들어지게 된다.
이제 하나하나의 요소들에 대해서 간단히 알아보자.
Environment (환경)
환경을 2가지로 나눌 수 있다.
- Fully Observable Environment : agent가 직접적으로 모든 환경을 관찰 가능
- Agent State = Environment State
- ex) 바둑판은 상대방과 나의 돌을 모두 볼 수 있음
- Partially Observable Environment : agent가 간접적으로 환경을 관찰, 부분적으로 환경을 관찰할 수 있음
- Agent State ≠ Environment State
- ex) 포커는 나의 카드만 볼 수 있고 상대방의 카드는 볼 수 없음
환경에서도 결정론적인 환경인지, 확률론적인 환경인지 구분지을 수 있다.
- Deterministic Environment : agent가 action a를 했을 때의 결과값인 next state가 정해져있음
- Stochastic Environment : agent가 똑같은 action a를 했을 때 next state가 확률적으로 정해짐
- ex) 빙판길에서 걷는 action을 했을 때, 계속해서 걸어가는 state, 넘어지는 state, 미끄러지는 state 등의 여러 경우의 수가 존재하고, 하나의 action 에서 여러 state가 발생될 수 있다.
State, Observation (상태)
state와 환경을 햇갈려 할 수도 있는데 분명한 차이가 있다.
Environment는 불필요한 정보까지 모든 정보가 포함되어 있는 데이터이고, state는 그 환경에서 agent가 action을 하기 위한 정보만 포함되어 있는 데이터를 의미한다.
tesla가 자율주행을 할 때의 상황을 예를 들어 보자면
도로의 상황을 Environment 라고 할 수 있다.
보행자, 자동차, 장애물 모든 도로의 정보가 다 포함되어 있다.
그런 환경 속에서 agent가 가속을 할 것인지, 브레이크를 밟을 것인지, 차선을 변경할지 등의 action을 하기 위한 정보만 포함되어 있는 것이 state라고 한다.
next action 결정에 필요한 정보만 포함되어 있는 데이터이다.
Agent
agent는 학습시키는 대상, 인공지능 이라고 할 수 있다.
agent는 Policy(정책), Value Function(가치 함수), Model로 이루어져 있다.
- Policy (정책)
- 함수 π(s) = a 로 표현할 수 있다. 해석하면 현재의 state S 에서 정책 π을 시행했을 때의 action a를 반환한다.
- state와 action을 매핑한 것으로, 최적의 policy를 학습하는 것이 궁극적인 목적이다.
- Deterministic (결정론적 정책) : agent의 action이 하나로 정해져있음 (앞쪽으로만 이동가능한 action을 하는 정책)
- Stochastic (확률론적 정책) : agent의 action이 여러가지 경우의 수로 나뉘어저 있고, 확률적으로 결정된다. (상하좌우 - 각각 30%, 30% 20%, 20% 확률로 action 할 수 있는 정책)
- Value Function (가치 함수)
- agent가 계산하는 값이고 정책 π를 따를 때, state s로 부터 예상되는 장기 보상의 누적 값(장기적 관점의 가치 판단이라고 할 수 있다. Goal을 기준으로 가치를 판단)
- ex) 야구 게임에서 번트를 치면 1루에서 아웃 될 가능성이 높아 low reward가 될 수 있지만, 장기적으로 볼 때 희생번트로 득점에 유리하도록 만들 수 있다. 이것을 Value Function(가치 함수) 로 판단하게 됨.
- reward를 주는 기준이 되며 action 선택의 기준이 된다.
- State Value function (상태 가치 함수), V^π (s) : state의 가치를 판단하는 함수
- Action Value function (행동 가치 함수) : state s 에서 action a를 취하는 것의 가치를 판단하는 함수
- agent가 계산하는 값이고 정책 π를 따를 때, state s로 부터 예상되는 장기 보상의 누적 값(장기적 관점의 가치 판단이라고 할 수 있다. Goal을 기준으로 가치를 판단)
- Model
- agent가 생각하고 있는 environment
- agent가 어떠한 action을 취할 때 어떤 reward를 받을지, 그리고 다음 state가 무엇인지 알려주는 역할을 한다.
- Model-free method : agent가 model을 모를 때
- ex) 미로를 2차원 관점에서 바라볼 때
- Q-learning, 몬테카를로 메소드, Actor-Critic 등을 활용해 학습시켜야 한다.
- Model-based method : agent가 model을 모두 알고있을 때
- ex) 미로를 3차원 관점에서 시작지점과 끝 지점을 한번에 볼 수 있을 때
- 계흭을 잘 세우면 됨
Action (행동)
- Discete action (이산적인 행동)
- 불연속 적인 값들을 반환하는 행동
- ex) 주사위
- Continuous action (연속적인 행동)
- 연속적인 값들을 반환하는 행동
- ex) 모터 컨트롤, 각도, 방향
Reward (보상)
앞에서 예를 들어서 설명한 것과 같이
agent가 action을 선택할 때 environment에서 반환하는 값이다.
time t의 reward를 rt 로 표시한다.
이를 통해 강화학습 문제를 해결하기 위한 접근 방식을 두 가지로 나누어볼 수 있다.
- Value Function Methods : state의 가치를 평가하여 좋은 policy를 탐색하는 방법. 더 큰 값을 가져올 action을 선택하는 policy를 발견하는 것을 지향한다.
- Policy Gradient Methods : policy 자체를 직접 학습한다.
'Data Science > 강화학습' 카테고리의 다른 글
| [강화학습] 벨만 방정식 (Bellman equation) (7) | 2024.10.04 |
|---|---|
| [강화학습] 가치함수(Value Function) (9) | 2024.10.03 |
| [강화학습] 결정론적 vs 확률론적 환경 (Deterministic vs Stochastic Environment) (2) | 2024.10.02 |
| [강화학습] 결정론적 vs 확률론적 정책 (Deterministic vs Stochastic Policy) (1) | 2024.10.02 |
| [강화학습] MDP(마르코프) 환경과 동역학(dynamics) (3) | 2024.10.01 |